<一> 背景
Tencent Blade Team在代码审计过程中发现了curl中存在两个可以通过NTLM远程触发的漏洞。这两个漏洞存在于curl在处理Type-2和Type-3消息的逻辑中。
这两个漏洞分别为:
(1)远程内存读取(CVE-2018-16890,https://curl.haxx.se/docs/CVE-2018-16890.html )
利用此漏洞,攻击者可以在服务器上远程获取客户端内存至多64KB的原始内存信息。而且因为连接可以多次进行,服务器理论上可以多次重复地获取客户端内存。
(2)远程栈缓冲区溢出(CVE-2019-3822,https://curl.haxx.se/docs/CVE-2019-3822.html)
利用此漏洞,攻击者可以通过服务器的认证消息对客户端进行远程栈缓冲区溢出。通过组合上一个漏洞,理论上攻击者可以对客户端进行远程代码执行(RCE)。
curl的作者Daniel在博客中提到“我觉得这可能是很长时间以来curl中发现的最严重的安全问题”(I think this might be the worst security issue found in curl in a long time.,https://daniel.haxx.se/blog/2019/02/06/curl-7-64-0-like-theres-no-tomorrow/)。
如果编译curl时,选择了使用openssl同时禁用md4,则有漏洞的代码不会被编译进去。在这些情况下的curl不受此漏洞的影响。
我们先从一些常见的场景和认证模式来介绍一下背景,这样可以更方便理解curl这些漏洞是如何工作的。
1.1 关于curl
curl用于命令行或脚本中传输数据。它还用于汽车、电视机、路由器、打印机、音频设备、移动电话、平板电脑、机顶盒、媒体播放器,是成千上万每天影响数十亿人的软件应用的互联网传输中枢(https://curl.haxx.se/语)。同时,它也可以作为组件(libcurl)在PHP、Python或者WordPress、Git等等软件中使用。
要触发这次提到的两个漏洞,客户端除了要使用有问题的版本以外,还必须支持使用libcurl或者curl来进行代理访问(通过NTLM认证)或者支持通过NTLM验证获取请求。
一般来说,curl的binary默认都是支持NTLM的。使用curl --version 查看,如果包含ntlm,即可以通过curl –ntlm -u “用户名:密码” 服务器连接远程服务器。

而libcurl则稍稍复杂一点,它需要开发者打开CURLAUTH_NTLM或CURLAUTH_ANY,以表示支持NTLM认证。
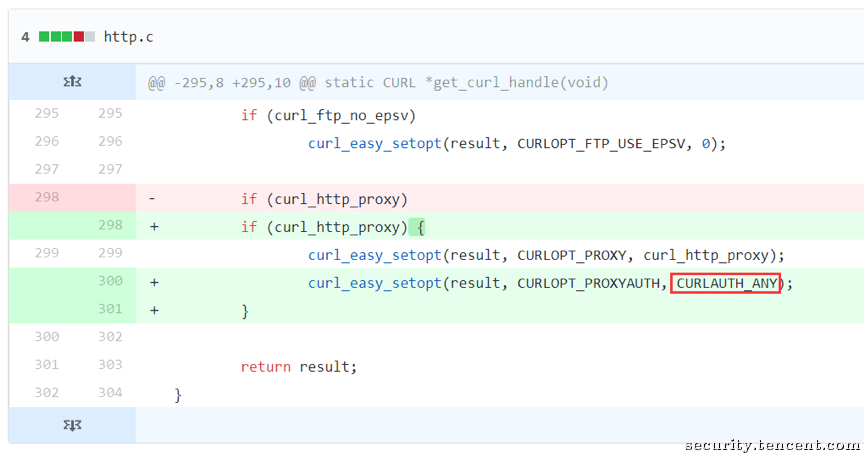
打开开关后要触发NTLM认证,必须通过命令行或cul_setopt指定用户名密码,或者直接在请求的url中指定。例如curl --ntlm http://用户名:密码@Server/。
NTLM常用于Windows上的身份认证,所以对有Windows机器的内网而言或者代理服务器而言,NTLM出现的频次并不很低。虽然说是身份认证,不过需要注意的是,要触发这次的两个漏洞,来自客户端的身份认证信息并不重要,因为服务器端是被黑客控制的,黑客并不在意客户端发来的是什么,只要按照既定规则发送攻击载荷即可。因此客户端哪怕发来的是错误的验证信息都可以继续触发漏洞。
黑客唯一需要做的就是,控制一台服务器。因为这是一组由服务器攻击客户端的漏洞。
客户端一旦使用有漏洞的curl+NTLM连接到黑客的服务器,黑客就可以攻击客户端程序。
举一些例子,为了称呼方便,我们在这里统称攻击者为H(Hacker),而被攻击的为V(Victim)。在这些场景下,你可能会和黑客“交手”:
- (1)你从网上随便找了一个公开的代理服务器H,但不幸的是这是一台黑客控制的服务器。然后把你的博客如WordPress配置了使用curl+NTLM代理的方式访问服务器H,则你的博客所在的Apache/PHP进程可能都会受到攻击
- (2)你使用了git客户端,配置使用了黑客的代理服务器H,认证过程中就会发生攻击
- (3)公司内网中,有一台服务器H被黑,其他服务器V通过curl+NTLM,向这台被黑的服务器发起网络请求时,H可以对这些服务器V进行攻击
- (4)你的爬虫程序V使用了libcurl来连接一个远程服务器H,并且V打开了支持所有认证模式的开关,这样H就可以攻击V了
诸如此类等等。
前提只有:
(1)受害者V的客户端使用了有漏洞版本的curl(7.36.0~7.63.0)且支持NTLM;
(2)受害者V访问了黑客H控制的服务器,并使用任意账号密码(不正确也无所谓,但是需要提供)发生了NTLM认证流程。
1.2 关于NTLM认证流程
再介绍一下NTLM。在Windows网络中,名词NT LAN Manager(NTLM)表示一种微软的安全协议,该协议可为用户提供身份验证。NTLM是Microsoft LAN Manager(LANMAN)中的身份验证协议的后继者,这是一种较旧的验证协议。(https://en.wikipedia.org/wiki/NT_LAN_Manager)。
NTLM的核心认证消息分为三类,三类的消息各不相同,但是名字很直观。它们分别称为Type-1、Type-2、Type-3 Message。其中Type-1类似握手的步骤,Type-2和Type-3则用于服务器和客户端之间的登陆沟通。
使用NTLM认证进行网络请求的过程如下:
1: C →S GET ...
2: C←S HTTP 401 Unauthorized
WWW-Authenticate: NTLM
3: C →S GET ...
Authorization: NTLM <经BASE64编码的Type-1消息>
4: C←S HTTP 401 Unauthorized
WWW-Authenticate: NTLM <经BASE64编码的Type-2消息>
5: C→S GET ...
Authorization: NTLM <经BASE64编码的Type-3消息>
6: C←S HTTP 200 OK
即:3~5为实际的认证过程。客户端(C)会发送Type-1消息和Type-3消息给服务器(S),而服务器会发送Type-2消息给客户端。
Type1、2、3三类消息的结果都是由之前消息的内容所计算而来的。
具体可以参考微软的文档:
https://docs.microsoft.com/zh-cn/windows/desktop/SecAuthN/microsoft-ntlm
curl官方已经发布了详细的漏洞通告。因为这两个漏洞的发现和利用仍然有许多有趣而且值得开发人员警醒的地方,所以我决定写一篇writeup来介绍一下漏洞的发现过程和思考。
<二> curl的客户端版“心脏滴血”CVE-2018-16890
这个漏洞和“心脏滴血”有那么几分相似。虽然“心脏滴血”是泄露服务器上的内存,而curl是泄露客户端上的内存,但是成因、效果上都能看到“心脏滴血”的影子。
这个漏洞位于lib/vauth/ntlm.c: ntlm_decode_type2_target,问题在于处理传入的NTLM Type-2消息的函数没有正确验证传入数据,最终导致了整数溢出。使用该溢出,恶意的NTLM服务器可以欺骗libcurl接受错误的长度+偏移组合,这将导致缓冲区读取和写入越界。
细节如下:
当用户尝试连接到启用了NTLM的服务器时,服务器将设置target_info_len (0~0xffff)和target_info_offset (0~0xffffffff)来回复Type-2消息。请注意,在Type-2消息中,长度和offset都是可以被设置的。
而这两个值恰巧又都是unsigned long,因此此处的验证并不正确:

如果target_info_len + target_info_offset = (unsigned long)0x1 00000000,则结果为零(高位1溢出),0在这里一定会小于“size”(消息长度)。
要触发整数溢出,target_info_offset的值必须介于0xffff0001~0xffffffff之间,因为它是长整形,这也代表它也一定会大于48。所以这里的两处安全保护全部会被绕过。
从而触发这里的越界读写

2.1 读取越界→绕过ASLR
我们先说越界读的问题。可以看到这里target_info_offset虽然定义成了无符号数,但是在方括号的数组索引中,它实际上还是有可能会扮演一个有符号数的角色。
当软件是32位的时候,方括号中的数字等价于signed long类型。
当软件是64位的时候,方括号中的数字等价于signed long long类型。
先以32位为例,假如offset是0xffffffff,这里memcpy读取到的实际上是buffer[0xffffffff]即buffer[-1]的数据,相当于向前读取了。
而如果是64位程序,则相当于从buffer[0xffffffff]处读取了数据。
数据存放在target_info中,在下一个NTLM Type-3消息返回给服务器时,curl将把这次读取到的内容发送回远程服务器。
根据len + offset的约束,读取的数据至多可以有64KB大小(0xffff字节),但是可以多次重复触发泄露。每次泄露的位置根据内存分配算法的不同,从而有所不同。因为消息会被base64编码,所以后面的堆数据会原样传递给远程服务器。
通过多次泄露,远程服务器基本可以知道客户端的内存布局。而且,一般情况下可以根据获取到的curl版本以及泄露的堆内容来找到一些可以计算出基址的数据,从而绕过ASLR,为代码执行埋下铺垫。
<三> “可能是长期以来curl里最严重的安全问题”CVE-2019-3822
Curl的作者在博客中写道,这可能是长期以来curl里最严重的安全问题。这个NTLM Type-3消息中的栈缓冲区溢出非常有趣。它就是一个非常纯粹、“old-school”(传统)的栈溢出。就是memcpy直接拷贝了超过栈变量长度的数据导致了这个溢出。9102年了,为什么会发生这个问题?其中有几个值得深思的地方。

先介绍一下问题。问题出在lib/vauth/ntlm.c:Curl_auth_create_ntlm_type3_message()。创建传出NTLM Type-3标头的函数基于先前接收的数据生成请求HTTP标头内容。如果从恶意的HTTP服务器提供的先前NTLMv2报头中提取非常大的“nt response”数据,则输出数据可能比缓冲区大。
“过大的值”需要大约1000字节以上。 复制到目标缓冲区的实际有效负载数据来自NTLMv2 Type 2响应头。
而且,用于防止本地缓冲区溢出的检查的实现是错误的(使用无符号数学运算),因此它不会阻止溢出发生。
细节如下:
Curl_auth_create_ntlm_type3_message会调用Curl_ntlm_core_mk_ntlmv2_resp来获取Type-2中得到的消息长度,在Curl_ntlm_core_mk_ntlmv2_resp中有如下定义:


而不巧ntlmbuf是一个固定长度的栈上变量。因此这里会发生栈缓冲区溢出。
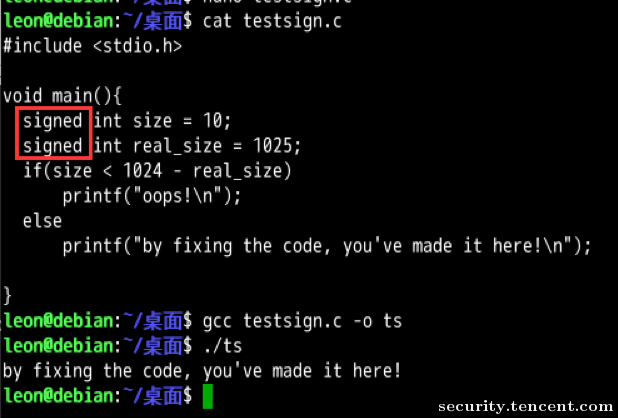
3.1 有符号/无符号数的错误比较→防护失效


因此实际上这个size < NTLM_BUFSIZE – ntresplen的判断并没有生效,从而导致了堆溢出代码的执行。
如果统一了符号,则结果就会变得不一样,程序会走到正确的分支上。这也是patch中所做的事情:
3.2 栈缓冲区溢出→任意地址、任意长度的数据读
你是否注意到这些挂在函数开头的一长串堆栈变量?仔细看一下这个函数的实现,你会发现一个有意思的事实:有漏洞的这个超大的函数,包含了数百行代码,数十个栈上变量。这个数字对一个栈漏洞来说非常有吸引力。
当漏洞被触发时,整个函数仅仅运行了1/3左右。这代表什么呢?分析完流程以后可以知道,如果我们能轻易地控制其他变量,就可以实现任意的远程内存读取。

如此信心十足是因为我们还有足足66%篇幅的逻辑可以控制。
当实现栈溢出以后,我们可以尝试覆盖ntresplen为一个负数或很大的值。这样,当下面代码执行的时候,size就会被我们控制(自此,函数中仅剩1个无关紧要的变量未被控制)。

假如我们覆盖了user和userlen,比如user覆盖成0x41414141。在以下代码执行的时候,我们就可以把0x41414141开始的userlen(可控长度)字节复制到缓冲区中。

3.3 远程代码执行
现在的问题来了,我们已经有了任意地址读的攻击方案,是否有其他什么方法可以让我们进行代码执行了?答案是:可以。
如果一个程序,有着这样的结构:
while(1){
if(cond)
foo();
}
那么只要它不退出,对于foo()来说, stack cookie每次都一样(当然栈每次也都一样)。如果foo()中可以触发这个漏洞,攻击者就可以得到cookie并向后覆盖。当然,攻击者也可以通过自己手动计算,方法很多,这里只是说其中一种最方便快捷的可能性。
可以简单做一下实验来证实,对如下代码:
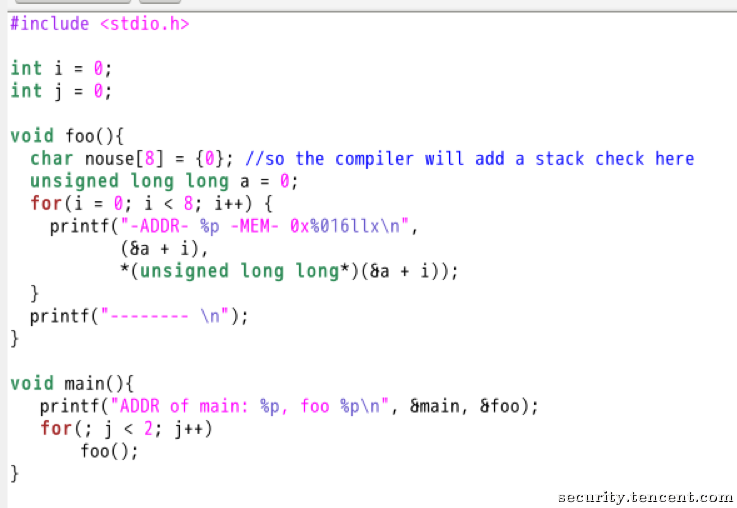
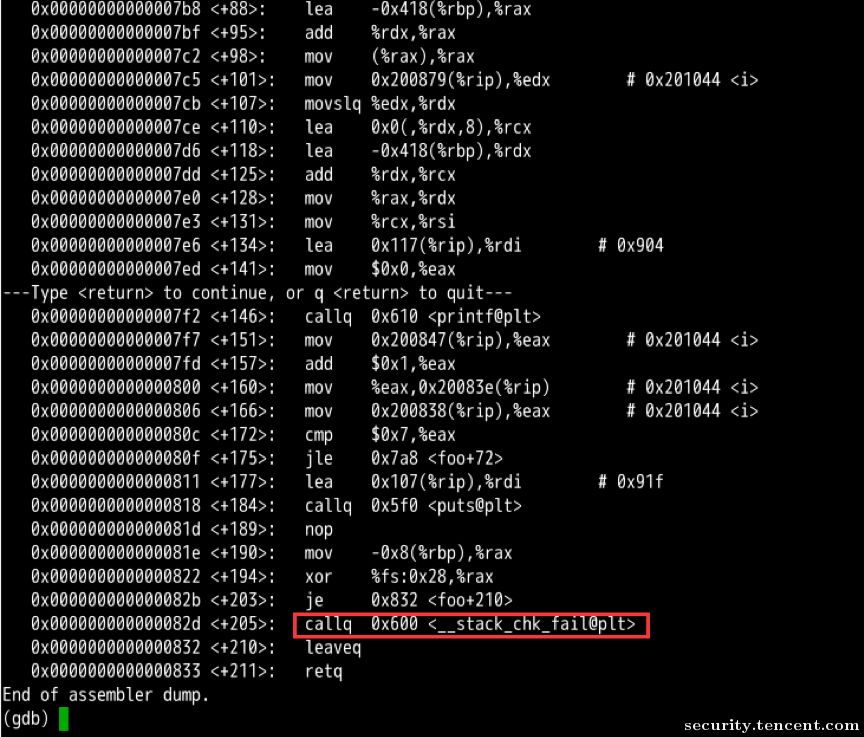
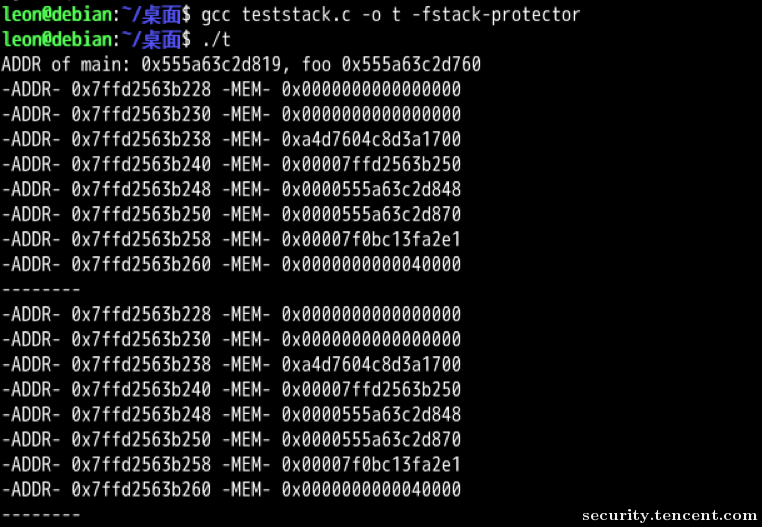
攻击的步骤就很简单了:
1、 利用CVE-2018-16890来获取程序的Base Addr,并找到堆栈的起始地址,计算出触发漏洞时的栈地址。
2、 利用CVE-2019-3822的3.2来获取执行时栈的内存。
3、 解出正确的栈内存,并保存。保存的数据包括正确的stack cookie。
4、 再一次发起请求时,用上一步保存的内容直接进行栈覆盖,并确保程序返回时,返回到攻击者可控的地址上(因为已经有几个寄存器可以控制,因此这步通常是stack pivot 的gadget)。同时,在栈上直接写入其他ROP gadget,方便后续进行ROP attack。
5、 代码执行完成。
如果攻击者能够控制客户端的行为那便是最好了,例如在root某些设备的时候,攻击者可以控制使用curl的组件重复发送请求。
实际利用时可能需要具体对待,例如,ROP gadget虽然可以基于curl或者PHP去找,但是你并不能确保远程机器上的curl和PHP都是未修改的。所以可能会有成功率的问题。
3.4 栈缓冲区溢出→堆缓冲区溢出
最后,如果开发人员已经注册了带有堆分配的回调,那么它还有可能变成堆缓冲区溢出。而注册带堆分配的回调也是常见的操作。
这个奇迹可能发生在下面的代码中,但是这需要看具体使用者是怎么实现convert_to_network的。我在这里只是提到这种可能,就不细说了。

<四> 两个本可避免的漏洞
漏洞均出于人。人是代码的创造者,也是灾难的创造者。让我们简单分析一下这些漏洞是如何产生的,而它们为什么本可以避免在代码中呆那么久的时间。
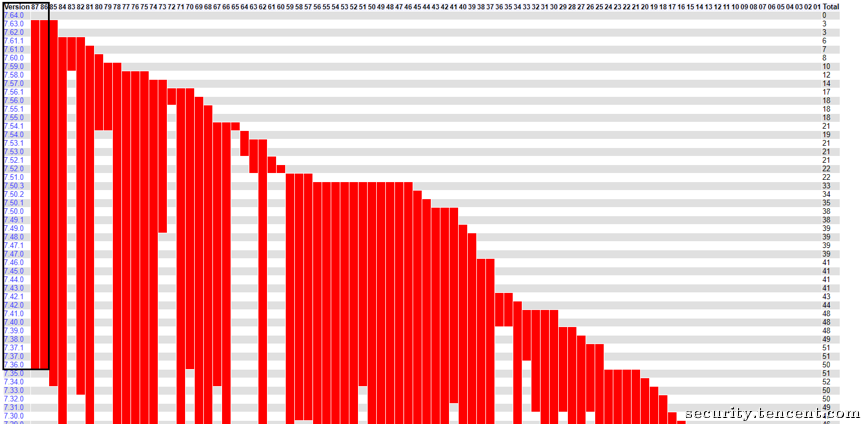
4.1被忽视的编译器警告
不要忽略编译器的警告。编译器之所以给出警告,正是代表着代码已经存在了歧义,虽然开发者可能有A型抽象的理解,但是运行的时候难免会变成机器遵循规则执行机器码的B型具体的解释。
其实这个问题单独抽出来就很容易想明白,有符号数与无符号数相加相减,到底代表什么?为什么描述同一个状态的缓冲区变量,一个“大小”可以是负数,而另一个“大小”却只能是正数?与其解释给自己或者小黄鸭,不如直接在代码上就规范好所有同类的东西的类型。
4.2过于隐蔽的宏定义
因为是人工审计,我习惯只在*.cc里面搜索,以至于这次差点漏过了这个缓冲区溢出(这个宏定义于.h文件中)。
它的问题出在这个宏给人的感觉就是,它就是一个常量,一个类似于#define PI 3.14的常量。但实际上它不仅值会变,而且还参与了很重要的逻辑的运算。
如果语义上要定义一个动态可变的参数,出于安全考虑,我更建议定义成函数样式,如:
#define LENGTH(X) (1 + 2 + (X) - 3)
或者,只把不变的部分定义成宏,如:
#define HEADERLEN (1 + 2)
#define SUFFIXLEN (3)
Len = HEADERLEN + x – SUFFIXLEN;
这样,当代码中出现这个宏的时候,基本一眼就能看得出来至少这东西的值可能是会变化的。以免在自己动态调试的时候都可能看花眼略过去。
4.3过长的函数
最后,开发同学们可能都知道,一直会有人强调不要写一个好几百行、功能复杂的大函数,而是要把函数分离开。但是深层次原因除了这样很难阅读或维护,还有其他的嘛?这里从安全上补充一个建议:为了安全起见,建议不要写如此庞大的函数。
从安全角度来说有什么影响?就像本文的例子一样,因为函数的栈帧中有太多的局部变量,一旦某个变量发生缓冲区溢出,或者其他什么变量发生了Out of bounds存取,极有可能会影响到其他局部变量的值。
而如果把函数分成很多小函数,即使发生了栈缓冲区溢出,因为有Stack cookie的保护,攻击者也不太可能会直接影响到其他函数中的栈帧(因为在调用到那里前就会因为cookie不符合程序直接崩溃)。
当然,关于大函数,这一点可能是利也可能是弊。我们的例子这种,如果攻击者在函数很靠前的位置就控制了你的函数,那后面这部分代码很有可能会帮助攻击者完成更复杂的功能。当然,弊端就是根据实际情况,后面的代码也有可能会给攻击者设置障碍。
<五> 结语
对于一些第三方组件,我们在使用的时候也许都会假定他们很安全,可能觉得它没有那么危险,但如果当它们与PHP或者其他你熟悉的软件结合起来,那后果可能都是十分严重的。
任何的远程代码执行、内存泄露,都可能造成另一个特定的攻击客户端版本的“心脏滴血”。
感谢Tencent Blade Team和团队的技术氛围,研究和讨论中我逐渐发现,这些问题的根源很多是来源于开发者的开发习惯上。我也曾经有几年在做开发,看别人代码不那么容易,但看自己代码更难。我也写过不少有安全问题的代码,开发不易,测试不易,坚持不易。不过即使不易,我觉得仍要坚守开发的规范,这个既避免自己之后还技术债,也是对产品形象的负责,和对用户的负责。
最后,也附上CURL官方的修复方案。
(1)受影响的CURL: 低于7.63.0且开启NTLM认证的CURL
(2)按照优先顺序立即采取以下操作之一:
A-将curl升级到版本7.64.0。
B-将修补程序应用到您的软件上并重新编译。
PATCH
https://github.com/curl/curl/commit/50c9484278c63b958655a717844f0721263939cc
PATCH
https://github.com/curl/curl/commit/b780b30d1377adb10bbe774835f49e9b237fb9bb
C-关闭NTLM身份验证
Daniel的修补代码都十分巧妙,非常简单有效,因此除了升级,PATCH也是一个比较好的备选方案。当然,如果你不需要NTLM,关闭它是最直接的避免此漏洞的方案。
具体仍请参考curl官网公告:
https://curl.haxx.se/docs/CVE-2018-16890.html



评论留言
1