作者:【腾讯安全平台部】 riusksk
引言
Fuzzing平台的价值思考
协同Fuzzing平台的设计思路
Fuzzing三要素
目标:攻击面分析
策略:变异之法
样本的收集与筛选
效果
总结
引言
近年来,无论是工业界,还是学术界,Fuzzing技术的应用都非常广泛。每年的BlackHat、OffensiveCon、CCC等工业界顶会以及学术界四大顶会( S&P、CCS、Security、NDSS )经常可以见到Fuzzing相关议题。Google Project Zero也公布其近5年的漏洞挖掘方式占比,其中Fuzzing占比37.2%,手工占比54.2%,其它占比8.6%,这对于高产的P0来说,37.2%的占比已经意味着不少漏洞了。按Project Zero官方公布的bug列表来看,当前共有1975个漏洞公开(包括一些无效、未修复的, 这里仅作粗略估算),按37.2%来算,大约有735个漏洞是通过Fuzzing挖掘到的,着实不少的数量,况且大多是高质量漏洞。所以说,Fuzzing依然是当前安全界所热衷的漏洞挖掘方式。
本文主要探讨下企业内部关于Fuzzing平台建设的一些想法,个人主要是想表达一个观点:协同Fuzzing,即整合企业内部各工种(开发、测试、安全、运维等等)的力量,将Fuzzing合入CI构建中,通过DevSecOps协同模式来完成产品的Fuzzing工作,以便将漏洞消除在上线前阶段。
Fuzzing平台的价值思考
虽说Project Zero超过一半是人工审计发现的,但对于企业内部,项目之多,代码语言和代码行也是非常之多,很难单纯靠人工来解决的。量级的变化,自然会导致自动化需求的诞生,才能更加高效地发现、消除和监管企业内部的代码风险。
产品从开发到发布,涉及到多工种协作,如果能让他们一块参与到安全工作当中,那么有时也可以弥补安全人力的不足,同时让非安全出身的业余选手也能干专业的事,帮助安全人员覆盖更多的攻击面测试,提升漏洞发现率。
安全人员参与到产品的整个研发流程当中,可以将发现漏洞的时间线提前,有助于在产品上线前发现并解决安全风险,提高产品安全性。
协同Fuzzing平台的设计思路
以往我们在帮业务产品作安全测试时,开始前业务同事会提供文档资料或者开会分享产品功能设计的方方面面以及担心的安全风险问题,安全同事需要花时间消化,前期双方都需要消耗不少时间成本,况且在有限的时间内,对产品的攻击面剖析也不一定足够到位。
假设当前需要对产品进行Fuzzing测试,一般需要一个支持命令行的测试程序,通常称为harness。开发或者测试的同学可能本身就会开发有相应的测试程序,如果没有,安全测试人员就得自己开发,有API或者源码都好办,没有的话,可能还得做Hook。
对产品最了解的,一般当属开发同学。所以,如果开发者在开发完相应功能后,开发以及质量测试人员若能够编写相应的接口测试程序,将对于安全测试会有很大帮助。一方面是工作效率的提升,另一方面是测试面的覆盖广度提升。
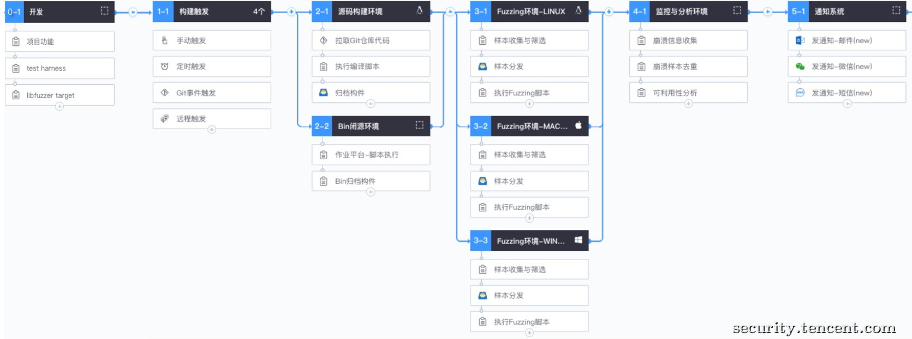
如此之后,我们可以设计出协同Fuzzing平台的工作流水线:
1.开发阶段:开发人员编写相应的harness程序,尽可能覆盖用于解析外部数据的处理函数。直接开发或者使用libfuzzer等安全测试库进行开发均可,安全人员也可定期对其进行安全培训,指导libfuzzer等工具的使用;
2.构建阶段:对于源码编译场景,支持多种构建触发方式,最佳的方式还是基于git事件触发,即提交代码后触发,然后将源码下载到指定的构建机编译,开发者需要配置编译命令,此处也可以开启ASAN或者AFL编译等功能;对于非编译场景,则直接提供相应的可执行程序下载地址,将其归档 打包至用于Fuzzing的服务器上;目前,“腾讯CI”已将构建功能嵌入到自家git平台“工蜂”上,提供覆盖所有主流编译工具和语言,因此未来其在安全领域上的应用还有发挥的空间。
3.测试阶段:配置相应的测试命令,即harness程序的参数,以及运行环境,包括Windows、Linux、macOS,如果硬件资源丰富的话,Android和iOS又何尝不可。提交在服务器上布署好常见Fuzzer工具(afl/libfuzzer/honggfuzz等等),或者自主开发的其它Fuzzer,同时部署一些常见文件格式的样本库。对于特殊数据格式,比如自定义协议/文件格式,最好由开发或测试同学提供,否则只能安全测试人员去解决,一些提取样本数据的方法后面会介绍。
4.告警阶段:若发现崩溃,则作二次运行确认,确认二次崩溃则告警出来,可邮件、工单、微信等多种方式,将运行命令参数、崩溃场景的栈回溯、可利用性分析等基本信息同步出来。对于崩溃容忍度较低的产品,可设置“质量红线”,去重后的崩溃数量超过多少个禁止发布。开发修复漏洞后,继续从第一步的开发阶段开始继续循环下去,直至无新漏洞发现。
Fuzzing三要素
Github上已有很多知名Fuzzer被开源,圈内也有不少人借此挖到漏洞,直接基于现成工具,或者二次开 发挖到的都有,也有人借鉴思路自主开发新的工具。对于一款新漏洞挖掘工具的发布,多数人可能会认为,开源作者应该是已经挖完漏洞了才公布的,应该已经挖不到0day了。但有时你又会发现,老树开新花的事情还是很常见的。那么决定Fuzzer能否挖到漏洞的关键因素有哪些?根据个人经验,笔者觉得主要有三要素:目标、策略、样本。
目标:攻击面分析
对于企业内部产品的测试,直接找开发要设计文档,甚至源码,都可以帮我们快速分析出攻击面。面对黑盒测试时,尤其是主流软件/系统的Fuzzing测试时,能够让我们参考的主要还是其官方文档,比如MSDN、Apple开发文档、Acrobat Javascript API手册等等。当初winafl诞生时,从MSDN找API去Fuzzing的方式屡试不爽,运气好的,一个API拿10个CVE也不是没干过;Apple开发文档中的系统的各个模块介绍,github上的示例代码等等,无不成为寻找攻击面的最佳途径;还有Acrobat 一个JS API产生好几个漏洞的情况,也有人直接写脚本分析API手册,提取API模板作Fuzzing;其它系统平台上写爬虫提取系统函数原型模板,作驱动Fuzzing。
这些从官方手册,以及官方放置在Github的示例代码,无不成为最佳的目标攻击面分析途径。如果你搞过上面这些,应该明白我在说什么。
除了文档,一些业界公开的漏洞信息,比如Project Zero、ZDI、厂商的补丁公告等等都是挖洞方向标。在以上信息都缺失的情况,就只能人工逆向分析来寻找攻击面了。
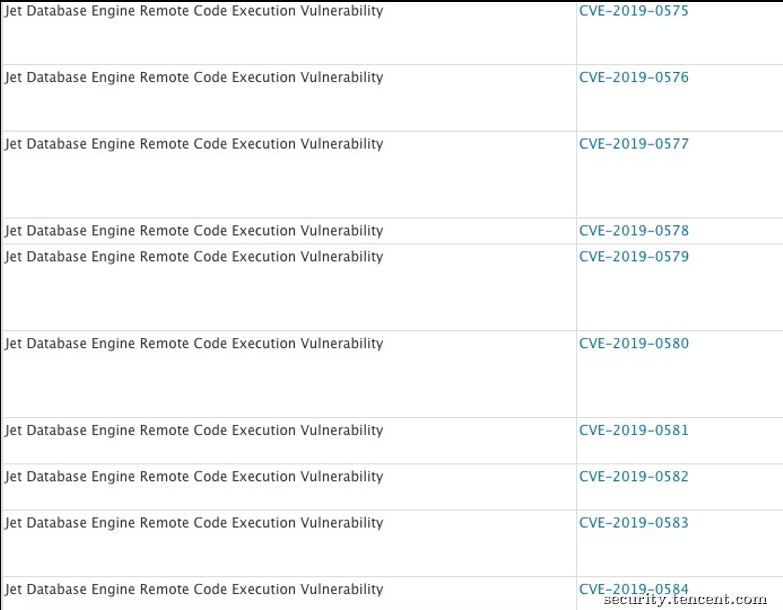
比如2019年微软的一次补丁公告中,出现了很多Jet数据库引擎的远程代码执行漏洞:
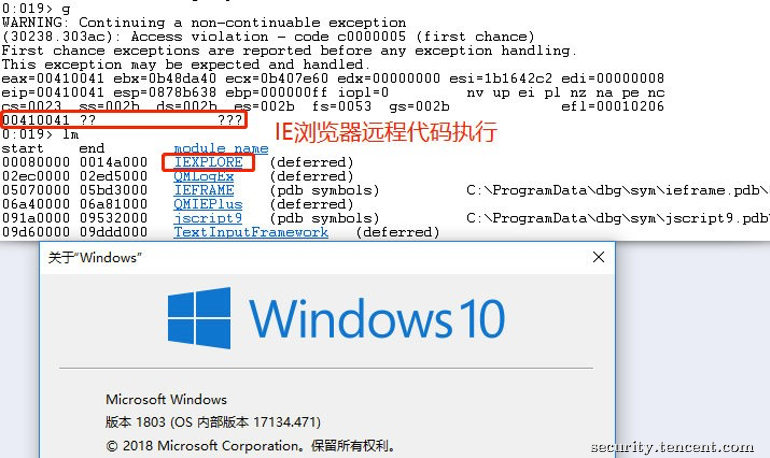
于是从MSDN入手去寻找可能存在的攻击面,然后用手上的Fuzzer框架进行Fuzzing,几小时之后直接挖到一个品相极佳的漏洞,因为生成的PoC直接控制了EIP:
策略:变异之法
常见的变异策略主要有以下几种:
1.基于暴力:随机数据替换、插入、删除、数值增减、边界值替换、拷贝覆盖等等,比如radamsa等;
2.基于模板:文件格式、协议格式、API原型模板、语法模板变异等等,比如peach、domato等;
3.基于代码覆盖引导:通过提高代码路径的反馈方式来优化样本,比如AFL、Libfuzzer等等;
4.基于语法树变异:通过AST语法树变异来Fuzzing语法解析引擎,比如Fuzzilli,该工具本身也实现基于模板和代码覆盖引导的功能。
除了以上常规的变异方法之外,有时需要针对当前的应急漏洞作新变异规则,或者适配特定的业务场景作定制化,这就要求我们的Fuzzer平台具备可扩展的变异策略插件开发,这种方式不仅可以社区化方式协同,企业内部也可以协同开发,类似oss-fuzz。
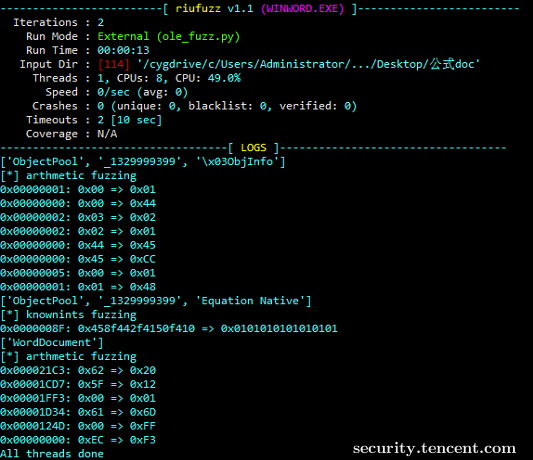
举个案例,2018年word公式编辑器开始流行起来,还被在野利用过。当时笔者就用python开发个针对OLE中“Equation Native" 的变异器,然后用riufuzz跑起来(riufuzz是笔者基于honggfuzz二次开发的fuzzer,2018及之前的新功能已在github上开源,之后开发就未开源了,大家可以自行发挥):
有时在变异前、变异后可能有特列的处理机制需要处理,比如pdf js fuzz,输入pdf可能得提取js再作变异,这是变异前处理;再比如png图片变异,变异后会导致crc校验失效,需要作变异后修复。还有对于复合文档中的某特定格式的文件变异后,需要重组打包,比如变异docx中的图片、pdf中的字体图片等等,此过程注意后缀名的变更问题。
样本的收集与筛选
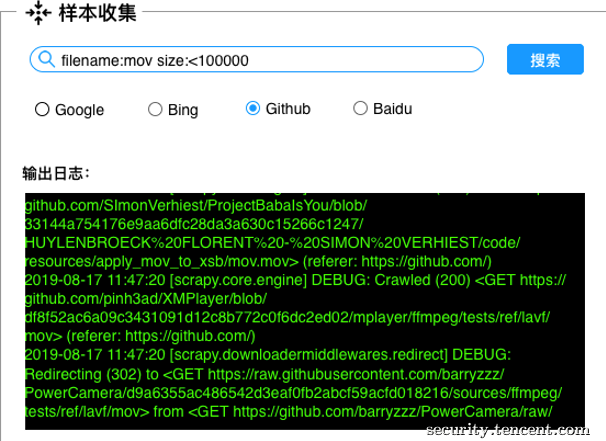
以前笔者都是手工去网上找样本去下载那种包含很多文件的压缩包,但这种方式太费劲了,用过想再更新又得再去找。后来就干脆用scrapy写个爬虫去搜索引擎搜索,像pdf、office文档、图片几乎都是爬不尽的,但它支持的文件格式比较有限。因此,我就改去Github爬虫,很多开发者在开发时,也需要一些 测试样本来验证,因此项目内经常包含有各种文件格式的样本,但它的搜索结果只有100页,需要变换关键词(字典库、单词库、输入法词库等等)来搜索,但整体搜索到的数量还是没有Google等搜索引擎多,可以当作互补方案。
若是遇到如openssl这种特殊协议数据,以及其它非完整文件格式的自定义格式,一般就得通过源码加Log输出,或者Hook技术去dump出二进制流样本数据,以此作为输入样本。
当我们获取的样本过多时,就需要作筛选,以避免过多的无用测试。对于开源项目,用AFL的工具足矣,但闭源程序就需要自己实现,以下就是笔者基于pin开发的语料库蒸馏器,用C++和Python开发的,支持跨平台:
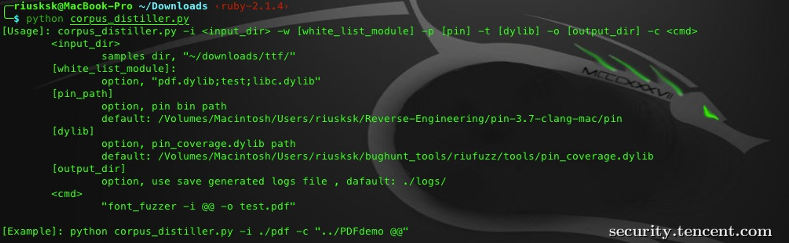
以macOS上的pdf样本筛选为例,整体效果还不错:

效果
基于上述方法论,笔者在近3年内,共获取国际四大厂商(Apple、Microsoft、Google、Adobe)70余次CVE漏洞致谢,其它一些厂商产品的漏洞暂且不计。
总结
本文主要介绍了协同Fuzzing的设计思路,将Fuzzing置入CI构建中的方法,并分享了决定Fuzzing效果的关键三要素:目标、策略、样本,对这些要素一一分析,并附相应的实战案例。未来,我们也会尝试多去实践和推广这种多工种协同Fuzzing的工作方式,并建设更加完善的平台管理控制系统,方便实现多人协同工作。
基于笔者水平有限,这套设计方案有些在企业内部实施的话,难免会有不足之处,欢迎业界同行斧正。



评论留言
3