引言
大眼系统是腾讯安全平台部从2008年起自主研发DDoS攻击发现系统,经过5年多的发展,已经发展成集DDoS攻击发现,入侵行为发现,基础数据分析于一身的网络流量分析系统,通过高效的多层负载分担,以集群的形式达到超大流量的分析能力。
本文由腾讯宙斯盾团队集体创作完成,旨在分享流量分析系统发展建设中的一些经验,受限于笔者的视野和水平,可能存在不足甚至错误的地方,希望得到大牛们的指正和建议。
综述
流量分析系统通过分光器,在IDC的核心路由器之前镜像一份流量用于分析,具体部署的位置已经在上一篇博客中做了详细的说明,在此不再赘述。整个系统从逻辑上大致可以分为收包,解包,DDOS检测,应用层预处理,以及应用层检测库等几大模块,如下图所示:

高速收发包
在软件层面看来,首先要解决的就是把所有流量都收上来,采用操作系统标准的协议栈显然是不现实的,在不同的时期,宙斯盾团队先后采用了内核挂钩,libpcap,libpfring,专用硬件以及DPDK的解决方案。

前三个均是基于1G的网卡,在保证处理不出现丢包的前提下,每台服务器大概只能处理500Mbps的流量,随着整体流量的不断增大,分析集群的规模也会迅速扩大,带来成本以及管理上的问题,因此团队开始寻求基于10G网卡的解决方案,此时Tilera,Cavium硬件平台开始进入视野。
经过对硬件的评测以及开发难度的评估,最后选择了Tilera做为新的分析系统的硬件平台,在此平台下,单机可以轻松做到10Gbps的流量分析和DDoS检测。但是随着对tilera平台的深入使用,逐渐开始暴露出CPU运算性能不足的问题,无法应对日益增多的应用层分析需求,项目组又不得不开始寻求新的解决方案。
同一时间Intel推出了DPDK,大幅提升了Intel通用X86 CPU的网络IO处理能力,同时考虑到X86 CPU在稳定性以及通用计算能力上也拥有较大的优势,而且开发人员也不需要去了解新的硬件平台,整个分析系统再一次迁移回X86平台。也就是目前主要在运行的流量分析系统版本。
借用一张DPDK的图,如图所示,DPDK做为用户应用程序和linux内核的中间层,为用户封装了硬件初始化,配置,内存分配,收发包等操作接口,使用Intel的CPU和网卡可以方便的创建出具备高收包性能的应用程序。
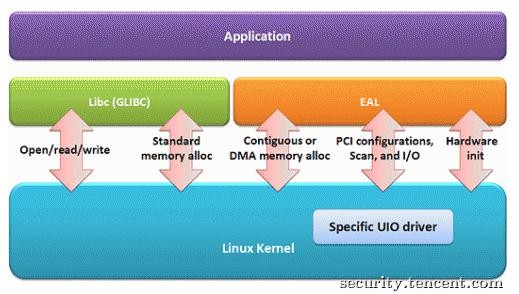
注:该图引自DPDK官方文档
几种方式的对比如下表所示:

DDoS检测
系统实时对到每个目的地址的流量进行统计,每隔一个统计周期,对统计到的流量进行汇总判断,对其中较大的流量,作为疑似攻击报出,再异步的根据目的地址的信息,如业务类型,平时正常流量等,判断是否为攻击。如果仍然判断为攻击,则需要进一步根据目的服务器的监控数据,判断攻击是否已经造成影响,如果有影响,则联动防御设备自动进行流量清洗,再根据防御的效果决定是否需要人工处理。具体流程如下图所示:

应用层分析
应用层的各个处理功能采用so库的形式挂载,如果各个so库都独自实现自己需要的功能,在实际运行中就会造成重复运行,浪费系统资源。因此在系统设计时,将超过两个模块都会使用的公用功能放到系统主程序中处理,也就是应用层预处理模块。目前该模块主要具备TCP流重组,应用层字符转码,http协议解析,URL访问统计。经过预处理后的数据才由各个模块调用。
具体的应用层检测功能在此不方便详细描述,因此本文仅对规则匹配引擎的实现做概要的介绍。
一般经常用到的规则可以分为字符串和正则表达式两种,如果对所有规则都逐条去匹配无疑会消耗大量的CPU资源,因此如何提高单条规则匹配的效率,减少规则的匹配次数,以及缩小规则匹配的范围就成为优化性能的重点。
首先就是正则引擎的选择,流行的正则表达式匹配引擎,基本可以分为NFA(非确定性有穷自动机)和DFA(确定性有穷自动机)两种实现,相对于NFA,DFA在缺失部分功能的前提下,拥有大约两倍的性能,因此我们的正则引擎采用DFA实现,对于多数正则表达式都可以直接支持,个别的需要人为去优化正则表达式的编写,实际中完全能满足功能需要。
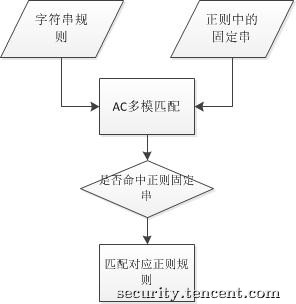
其次各个规则都需要明确指定应用的请求类型,如GET/POST或者所有类型,以及应用的范围,比如只匹配参数字段,或者全包匹配等。然后对请求类型和应用范围都相同的规则再进行进一步的组合,字符串类型的规则采用AC多模匹配算法一次匹配,而对于正则类型的规则,则从中提取固定的字符串部分,和字符串规则合并进行一次匹配,对于命中固定部分的数据,再去进行正则匹配,以此来减少正则表达式匹配的次数,显著提高规则匹配的效率。匹配流程如下图所示:
高性能网络流量分析系统的一点心得
1、合理拆分逻辑,按需分配资源
按功能来区分不同的工作线程,分配资源的时候,优先保证核心功能的正常运行,同时兼顾不同逻辑的开销进行系统资源的分配,即使在系统完全满载的情况下,也保证核心功能不受影响。
2、层层过滤,先轻后重,减少重逻辑处理的数据量
在不影响整体分析效果的前提下,根据处理逻辑的轻重调整顺序,将公用,资源消耗少的逻辑提前,同时,数据在向后的同时,一层层的丢弃不需要继续处理的数据,减少重逻辑需要处理的数据量,降低整体资源开销。
3、动态负载均衡,充分利用资源
防止木桶效应,根据各个线程的负载情况,进行动态的负载分担,最大化的利用系统资源。
4、分布式分析,集中式管理
分布式分析处理,提升整体处理能力,将判断逻辑以及管理集中,保证整理处理性能的同时,又能维持策略的灵活性。



评论留言
7